


Exposure Analytics
Real-time Event Analytics for Offline Marketing

Client
Jeremy Rollinson
Location
UK
Industry
Big Data
Core Technologies
Ruby Ruby on Rails jQuery MySQL PostgreSQLExposure Analytics
Real-time Event Analytics for Offline Marketing
Exposure Analytics is the first solution of its type – software platform for offline analytics. Using the unique suite of data collection technology, Exposure delivers key insights into how visitors interact with an event or retail space.
Challenges
In a modern competitive landscape, where marketing experts have the opportunity to measure essential website metrics like clicks or conversion rate, our client, Jeremy Rollinson, wanted to help bridge the gap between offline events and marketing specialists who measure their success. He decided to create a real-time analytics system that helps event organizers to collect useful, reliable data and effectively evaluate the success of events.
Our team needed to develop an efficient real-time analytics system to gather data on visitor behavior and then send collected data to an advanced cloud platform for analysis.
In a short time, we needed to:
- Gather and clarify requirements to define the core functionality and objectives for the product
- Conduct competitor analysis to form an effective marketing strategy
- Implement real-time analytics that would rapidly process a large amount of data
- Build a full-fledged digital analytics tool that relies on beacons and AI elements to provide image and facial recognition
- Ensure security to protect private data of clients
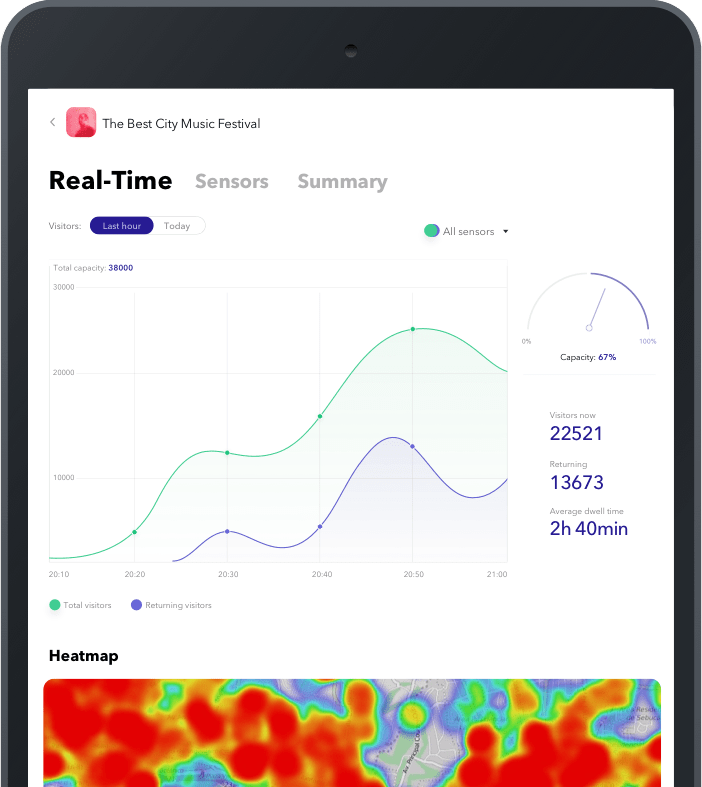
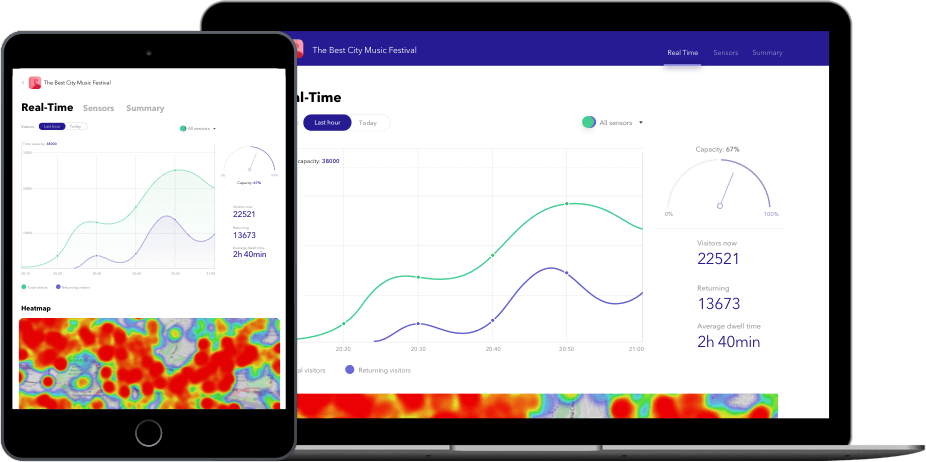
Full picture of visitor engagement
Wi-Fi sensors to track the visitor movement
Live dashboard
Event organizers are able to track important data as new/returning visitors, average dwell time, conversion ratio, etc
The digital event analytics to gain insights into visitors behavior
Solutions
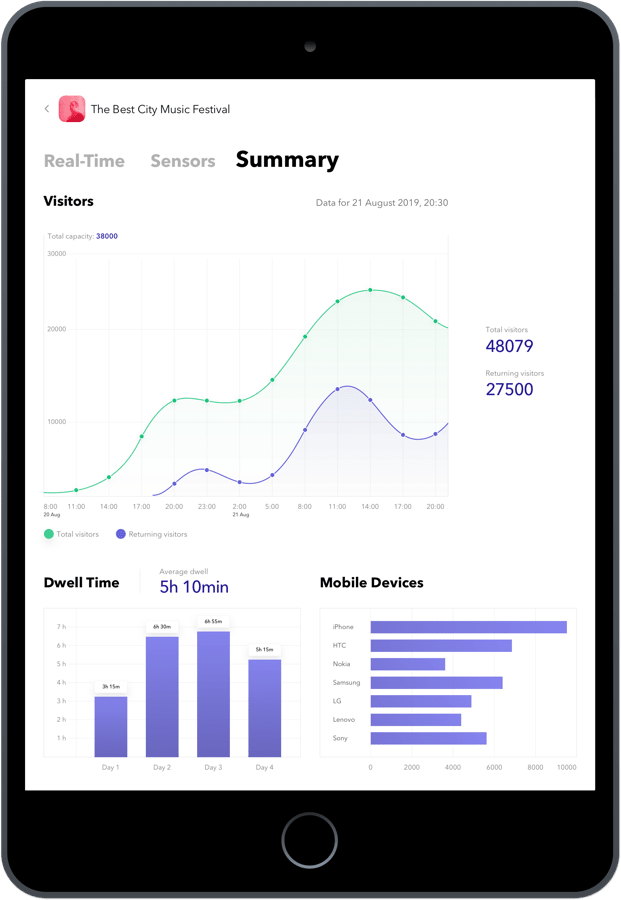
Our team implemented the vital functionality of real-time analytics system that allows for gathering unique metrics about visitor engagement and dwell time distribution as well as getting detailed statistical reports including conversion analysis and spatial comparisons.
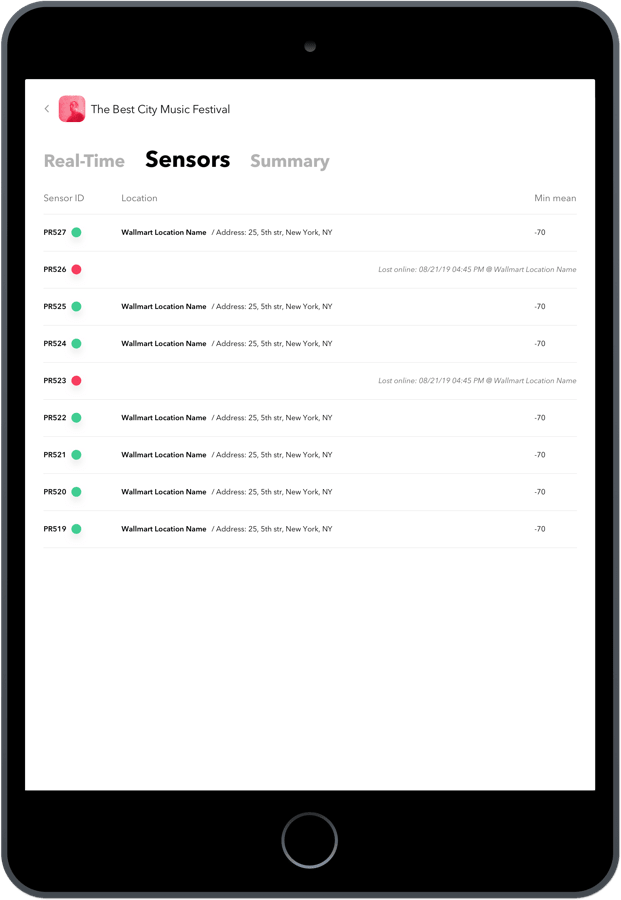
The digital analytics connects with video cameras and Wi-Fi sensors to track the visitor movement. The system gathers data about the number of visitors that pass by, identifies their faces and counts the number of visitors.
We provided the following solutions:
- Building a dynamic user interface that allows for updating various parameters on the dashboard without waiting for the page to reload
- Implementing quick data processing and system performance with the help of Elasticsearch.
- Combining several technologies (including beacons and AI elements), so Exposure works through a smartphone’s Wi-Fi network to gather data on visitor behavior. The raw data detected by sensors via unique Wi-Fi beacons is then sent to an advanced cloud platform for processing the data and turn it into useful statistics
- Building a live dashboard to enable event organizers and exhibitors to track important data as new/returning visitors, average dwell time, conversion ratio, and current capacity
- Implementing a heatmap to get a full picture of visitor engagement and find out what the most popular and the most engaging spaces or events are
- Creating a reporting tool to see more detailed statistical reports including conversion analysis and spatial comparisons
- Building a tool to track visitors' movement around space and find out the busiest routes over time
- Developing a tool for data encryption on the platform and on the sensors themselves to protect collected data
Technology Stack
-
Ruby
-
Ruby on Rails
-
Angular 1x
-
Resque
-
Unicorn
-
Puma
-
MQTT
-
Ionic Framework
-
Chef
-
Grafana
-
HipChat
-
Jira
-
Confluence
-
Shippable
-
JQuery
-
MySQL
-
PostgreSQL
-
AWS
-
more
Results
RubyGarage helped Jeremy Rollinson develop the digital analytics solution that retrieves data from Wi-Fi sensors installed on the territory of an event and processes these data according to a complicated mathematical model.
Today Exposure is a powerful analytic system that is used at the world’s greatest events by such companies like Honda, Philips, and Pepsi and processes more than 10,000 unique visitors per second.
Exposure Analytics helps event organizers and exhibitors gather unique and meaningful data to make their events engaging, valuable and profitable.
Exposure
The team at RubyGarage have played a critical role in the development of our analytics platform. Our work with them is based on a strong partnership, far more valuable than a traditional offshore development relationship. Their work is of an exceptionally high standard and the whole team regularly goes the extra mile to support our business. Whatever the challenge, be it technical or operational, RubyGarage have always delivered on time and on budget.
Want to develop a digital analytics solution?
Our Advantages
-
 Free & non-binding offer
Free & non-binding offer
-
13+ years in the development and service design market
-
160+ released projects
-
150+ In-house specialists
-
Needs analysis instead of sales talk
-
Valuable suggestions from experts in the field for your project